


Why Learning Rate Is The Most Important Hyperparameter In Deep Learning (And What Is The Most Popular Way To Configure It)
Most of us forget the basics and wonder why the specifics don't work

It all started with this tweet.

I am building a library to create prediction models for protein sequences by taking advantage of the recent explosion of pre-trained protein large language models (pLLMs). Similar to pre-trained LLMs but applied to biological sequences.
I was focused on the latest developments like the biggest models or the fanciest techniques (parameter-efficient finetuning). I was chasing shiny objects.
This tweet and the comments from top deep learning experts made me reevaluate my strategy because techniques come and go, but the basics remain unchanged. I need to focus more resources on getting the learning rate right first.
Most of us forget the basics and wonder why the specifics don't work
— Garrison Wynn
So, let's get to some basics
What’s the learning rate?
A model's prediction means nothing without proper weights and biases.
At the beginning of a training process, the model’s parameters (weights and biases) are initialized randomly or pre-trained for another task.
Then, at each training or finetuning step, the predictions calculated with the current parameters are compared with the actual predictions to calculate the error or loss. Finally, in the backpropagation step, we adjust these parameters using the loss so we can reduce it at the next step.
The amount of adjustment depends on both the loss and the learning rate.
This is why the learning rate is the most important hyperparameter to tune because it controls how well the models will learn. It sets how much to subtract or add to the weights and biases so the prediction for the next step is more accurate.
Let's show the effects of different learning rates with a clear, intuitive example adapted from Quora.
The effect of different learning rates
Imagine you are training a boy (the model) to classify cats.
You show him 10 cats, all with orange fur so he'll think all cats have orange fur. Now, you show him a black cat and tell him it is a cat (supervised learning). He'll think all cats are black if the learning rate is too large even though he has seen more orange cats while with a small learning rate, he will think black cats are outliers and all cats are still orange.
He'll need to see many more examples before changing his mind.
A desirable learning rate is low enough so the model can learn something useful but high enough to be trained fast.
This raises another question
How do you find the optimal learning rate?
We can use a learning rate finder from Pytorch Lightning [1] to find the optimal learning rate.
As described in this paper [2] we define the search space by setting the maximum and minimum learning rate, typical values [3] are less than 1 and greater than 10^-6.
Then the finder will do a small run for a few batches where the learning rate is increased linearly or exponentially to log the losses. This results in a learning rate vs loss plot that can guide your choice.
But, it is not recommended to choose the one with the lowest loss, instead pick something in the middle of the sharpest downward slope.
Here is an example from PyTorch Lightning. The red dot is what it’s lerning rate finder would suggest to you.
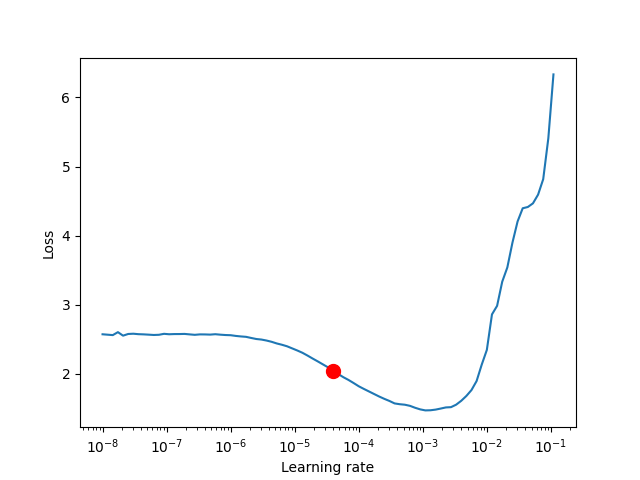
As you can see, it is simple to choose a good enough learning rate.
The learning rate should change over time
However, you shouldn't have a fixed learning rate during training.
What most researchers in the field do [4] is to have a warm-up step where you start from a value 10 times lower [5] than the one you found with the learning rate finder, for example, and increase it linearly over several batches until reaching the optimal lr.
An early warm-up stabilizes the training because at the beginning the loss might be large and can cause large weight updates if the learning rate is high.
Plus, what the model learns from the initial batches might not be representative of the entire dataset so gradually increasing it will prevent the model from being influenced too much by these early examples.
After this initial step, it is common to decay or gradually decrease the learning rate again to some minimum learning rate much lower than the initial learning rate.
This step improves model performance because, at later stages of the training, the weights are closer to optimal and only need small updates.
There are many more strategies implemented in PyTorch but what I have explained is by far the most popular one, what most practitioners do. It is called the One Cycle Learning rate policy [6].
This policy implements both linear and cosine decay.
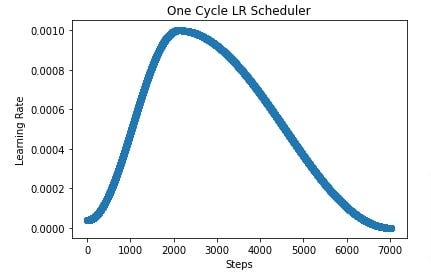
Here you see a plot of both decay functions using the default implementation in PyTorch when setting the max learning rate to 0.001.
It has the warm-up step reaching the maximum learning rate after the first 30% of the batches.
Then decreases using a cosine function for the rest of the batches until reaching a minimum that is even smaller than the initial learning rate.
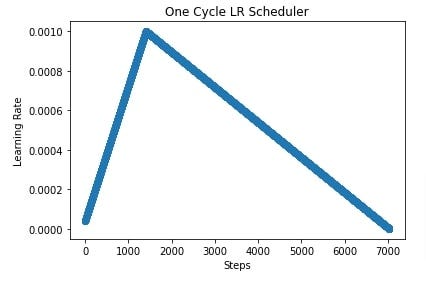
Here is the same plot using linear decay, which is the most popular one, even though the default in PyTorch is cosine decay.
[2] Cyclical Learning Rates for Training Neural Networks
[3] Practical recommendations for gradient-based training of deep architectures
[6] OneCycleLR
👋 Hi, this is Ruite. I write about wellbeing and mental health, python, and machine learning. Thank you for your readership 🎉.
If you enjoyed reading this post, feel free to share it with others! Or feel free to click the ❤️ button on this post so more people can discover it.
If you’d like to hear more from me, consider subscribing to my newsletter if you haven’t already